
Détail de la partie pré-traitement :
Cette partie pré-traitement a nécessité des développements spécifiques pour définir et mettre au point la stratégie à suivre pour l’interprétation des données des trois dictionnaires.
Premier éditeur
Un premier éditeur de règles a été développé pour les expressions phonétiques contenant les vagues. Cette éditeur permet de définir et de tester les règles à appliquer dans la transformations des expressions. Définition des règles de transformations (voir)
Cette interface permet de tester en fonction des formes phonétiques l’application des règles de transformations. Elles permet également de constituer des jeux de tests qui permettent de contrôler la non régression des transformations.
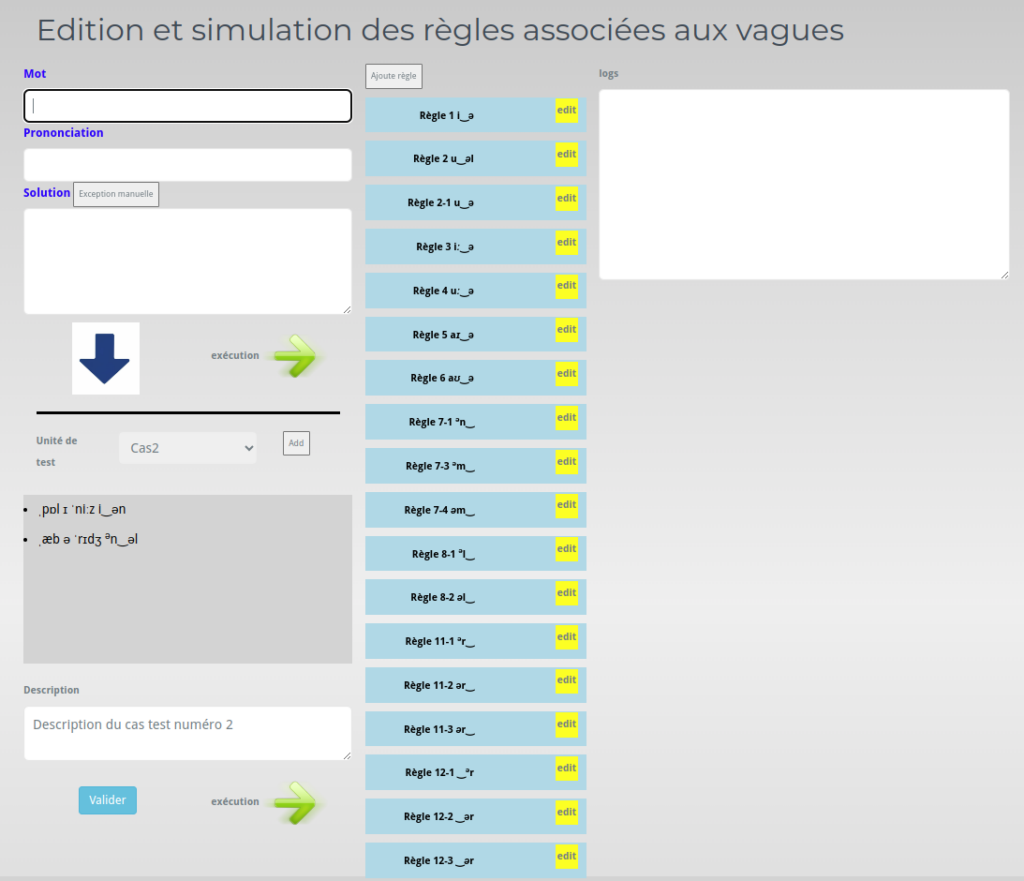
Deux compléments sur cette interface ont été développés : un pour gérer les exceptions et l’autre pour éditer et modifier les règles.
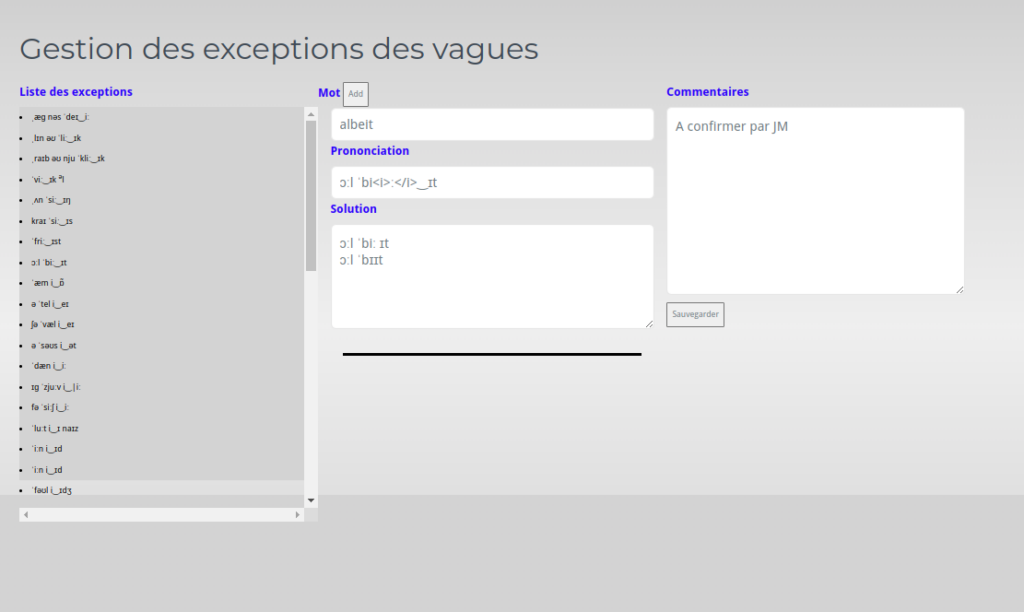
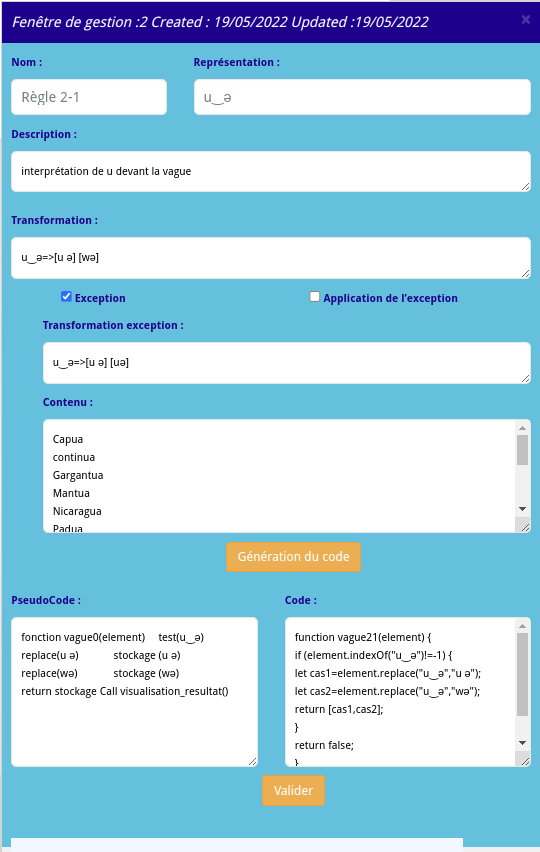
Dans un souci de rendre les choses accessibles aux collègues, une partie d’écriture directement du code Javascript a été autorisée et permet de compléter et d’adapter le traitement en fonction des objectifs.
Module de test du parseur avec les nouvelles règles :
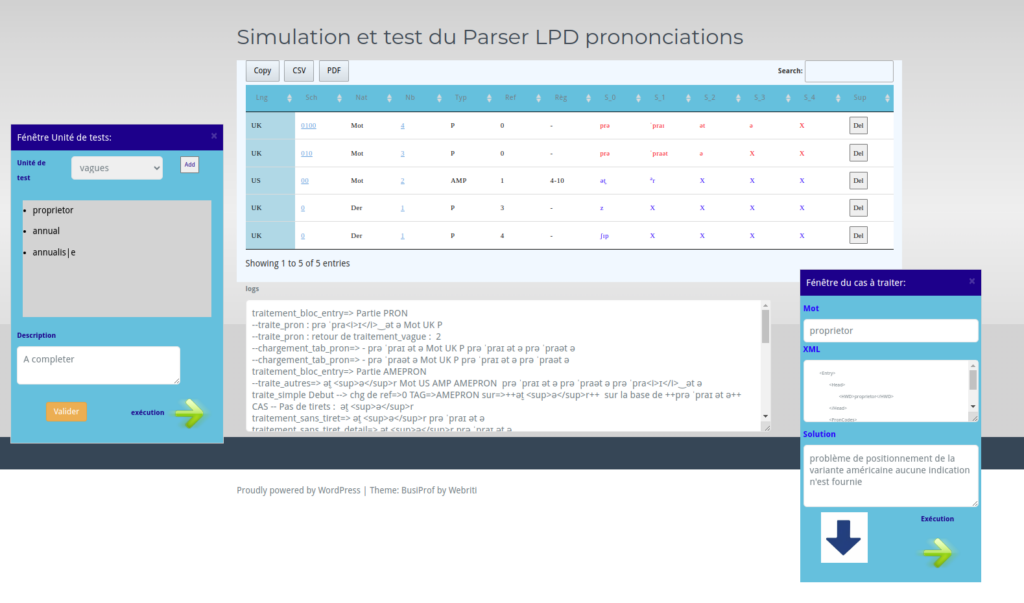
Deuxième éditeur : manipulation et contrôle des transformations phonétiques LPD
Un deuxième éditeur de visualisation des entrées LPD avec leur interprétation et leur forme complète a été développé permettant de vérifier entrée par entrée la bonne forme des prononciations et d’avoir un descriptif exhaustif. Plusieurs problèmes se sont présentés lors de cette opération, comme des formes non complètes, des erreurs de positionnement, des modifications implicites. Les règles de transformations ont été reconstruites une par une.
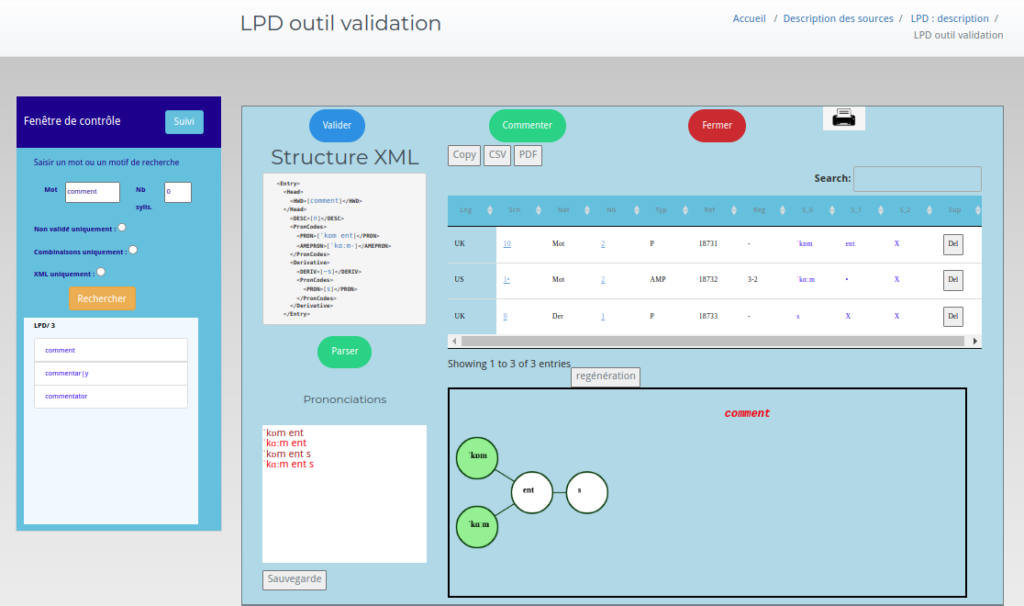
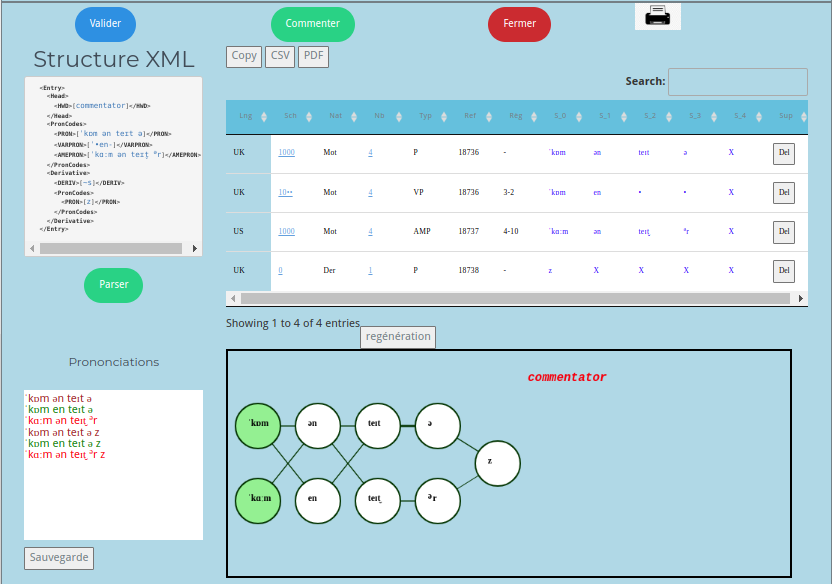
Un outil de visualisation graphique a été développé pour deux objectifs : vérifier les transformations et interprétations des formes phonétiques et de proposer une nouvelle façon de visualiser ces formes .
Possibilité d’extraction et de recherche selon trois axes combinés :
- graphie
- Schéma
- Phonétique
Représentation des résultats sous différentes formes :
- forma tabulaire
- forme d’arbre
Illustrations du module d’extraction (voir)