
L’objectif de cette plateforme est de proposer une méthodologie de construction d’un méta-dictionnaire sur la base des trois dictionnaires de langue anglaise.
L’approche privilégiée dans cette nouvelle structure est un format Web en évitant ainsi les inconvénients d’applications de type Standalone :
- mise à jour difficile
- travail collaboratif restreint
Cette nouvelle approche est plus d’actualité mais comporte également des difficultés de mise en oeuvre, de déploiement et de sécurité. Sachant que tout service informatique exposé est susceptible d’être une cible pour des personnes malveillantes, il est nécessaire d’avoir une attention particulière sur les aspects sécuritaires et de continuité de service.
Les objectifs sont multiples:
- accès à différentes étapes du pipeline par les collègues MP – Tours
- conserver une traçabilité des opérations de mise à jour effectuées
- de transformer les mécanismes d’interprétation et de transformation de façon itérative
- permettre un accès communautaire
- possibilité de définir des circuits de validation (des modifications ou ajouts)
- permettre des interrogations et exploitation des données
- profiter de représentations graphiques innovantes
L’architecture retenue pour cette version est une structure à trois niveaux :
- frontal –> sous wordpress
- Web service –> sous Spring Boot (Java)
- Base de données –> sous Mongodb
Le frontal a pour objectif :
- contrôler les accès aux fonctionnalités disponibles –> gestion de compte
- offrir des interfaces adaptées aux utilisateurs pour les actions de mise à jour
- permettre des mises à jour communautaire avec un circuit de contrôle qualité
- offrir des interfaces d’interrogation et des représentations innovantes de résultats
- offrir un espace communautaire et d’échange autour de ces données
- …
Le web service :
Est l’élément intermédiaire entre le frontal et le backend. Il contient toute la logique de stockage et de traitement des données. Il permet de relier le frontal à la base de données en favorisant une indépendance entre les deux. Le frontal ne sait pas comment sont stocker les données, il formule des demandes sur WS qui les interprète, les traduit et les soumet à la base de données. De plus, il permet d’ouvrir éventuellement des accès via des plateformes directement sous un format BtoB avec échange de token, ce qui devrait permettre d’offrir à d’autres plateformes les données engrangées et de permettre des alimentations directes de fonds sonore …
Le backend :
Cette partie est composée de deux éléments : une base de données de type NoSQL (Mongodb) et d’un espace de stockage pour des corpus sonores.
Chaîne de traitement proposée :

L’approche dans cette mise en oeuvre doit être une approche communautaire au regard de l’étendue du travail à fournir dans la vérification des informations issues des trois dictionnaires et de leur format spécifique.
Module de Visualisation et exploitation
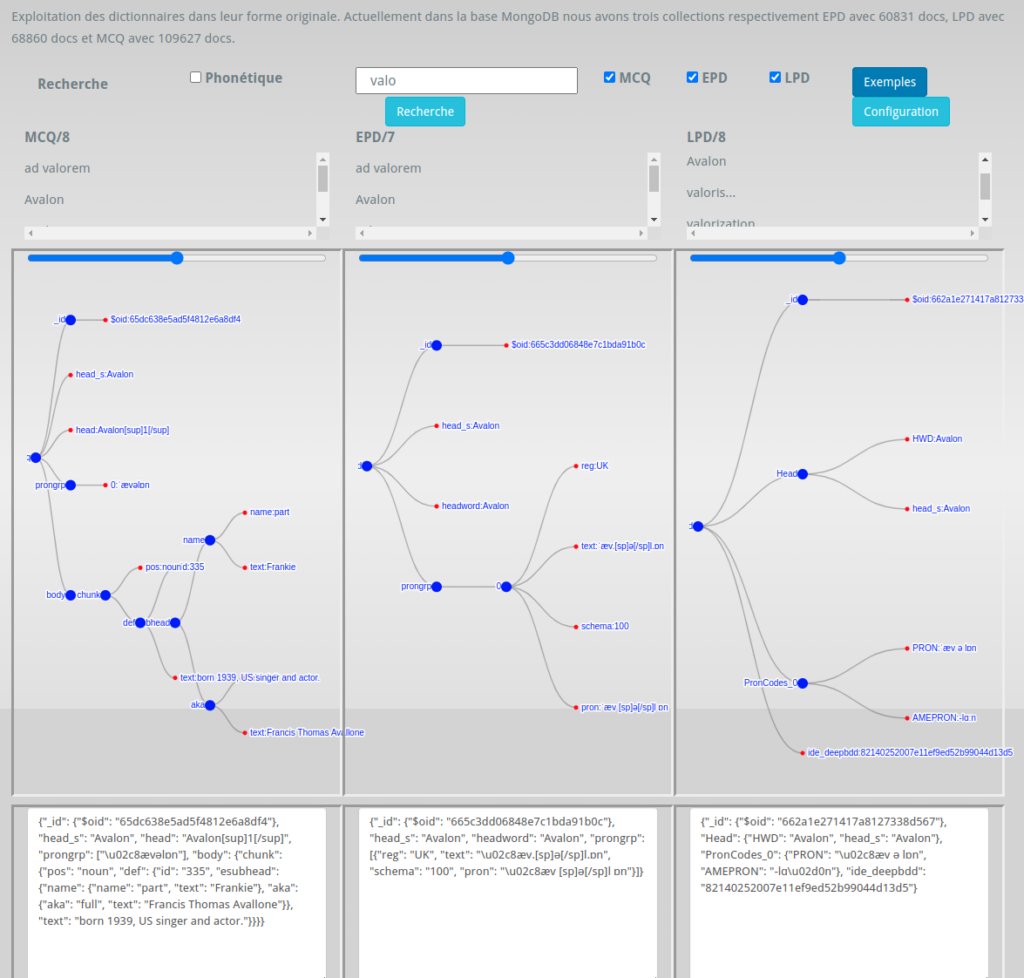
Module de d’extraction et de visualisation : cette interface travaille sur la version d’origine des données issues des trois dictionnaires. Ce module est conservé pour effectuer des vérifications à partir de la source d’origine.

Module de pré-traitements

Ce module est dédié aux étapes préliminaires de validation et de correction des données issues des sources. Dans notre cas chaque source a nécessité une introspection et une interprétation pour amener les données dans une forme plus facilement exploitable. On pourra citer du côté LPD l’interprétation des règles utilisées dans la description phonétique, des descriptions d’entrées fournies dans des balises sous forme d’imbrication, ….
Pour la partie EPD, l’utilisation de balises de type pron ou prinidx, l’utilisation de balises de type comment, pos dans lesquelles nous allons trouver des informations de différente nature;
Pour la partie MCQ, une transcription des descriptions phonétiques, une information trop riche pour la constitution de notre meta-dictionnaire ….
Module Parser

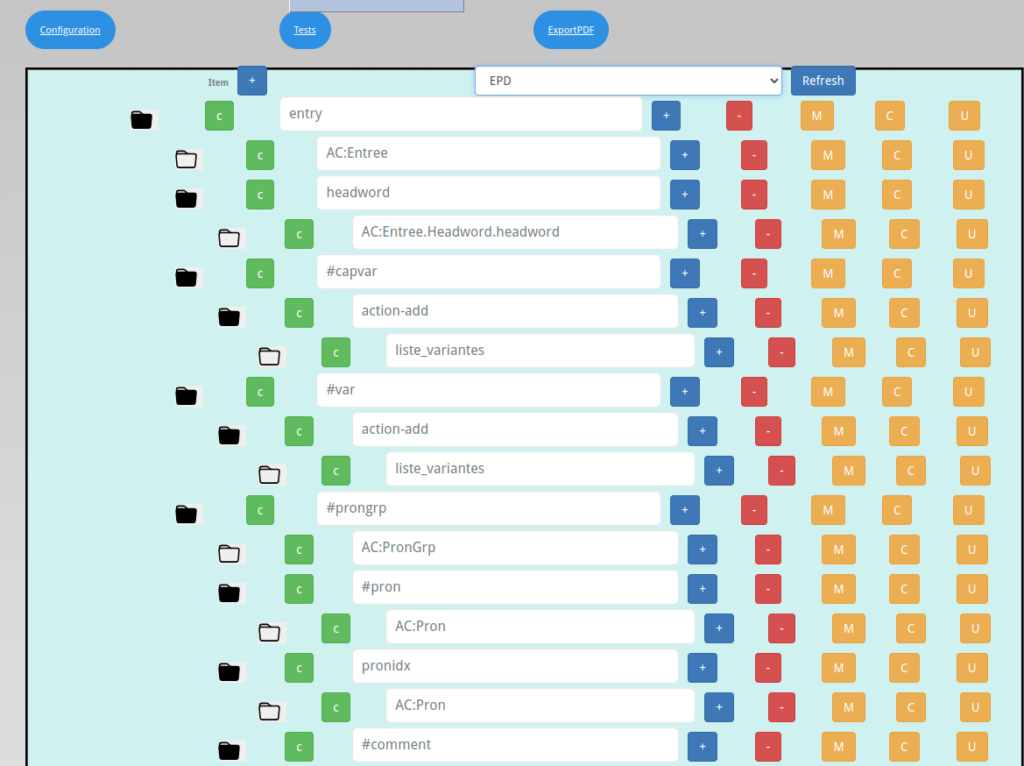
L’objectif de ce module est de fournir une interface aux collègues pour définir les règles d’appariement entre les versions des données sources et la version interne de la plateforme. Ce module permet d’indiquer quelle structure on retient pour notre plateforme et quelle transformation on applique aux attributs des sources.
Module Meta-données

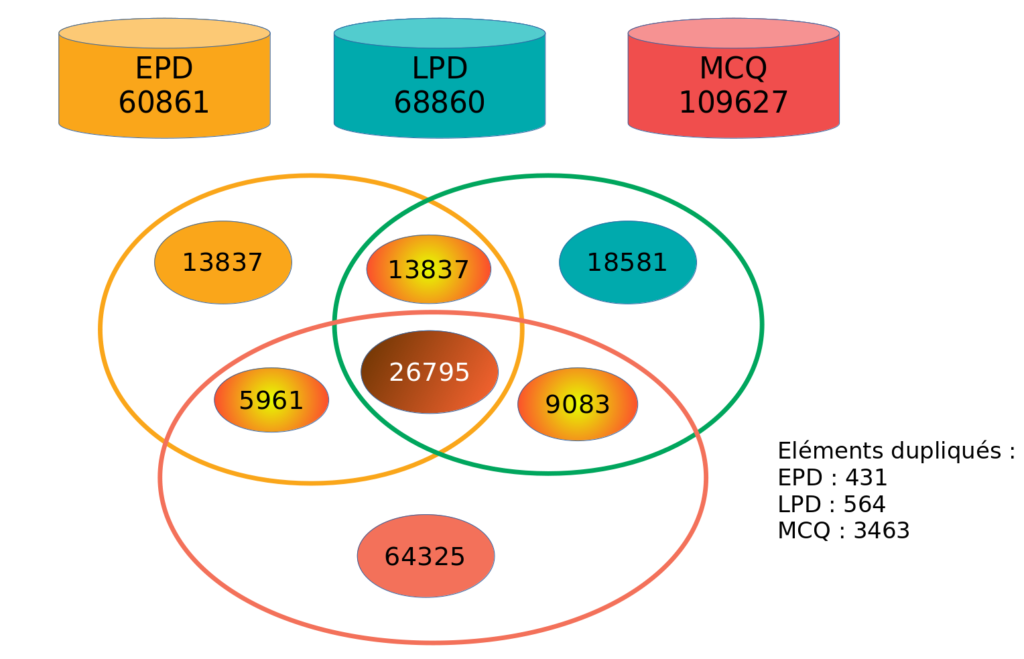
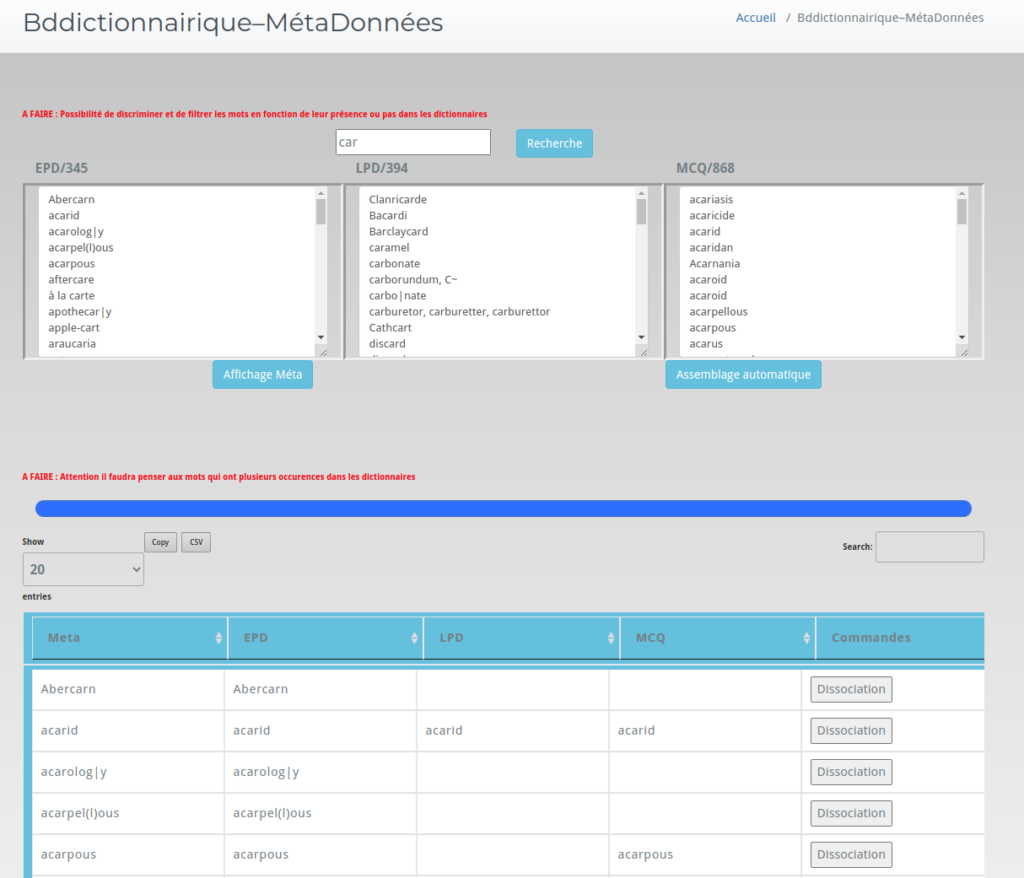
Une fois l’ensemble des sources déversées dans le modèle interne, on va devoir définir quelles sont les liaisons que l’on établit entre les différentes entrées. Une partie de cette opération se fera de façon automatique, mais dans certains cas les collègues pourront agir sur les liaisons effectuées pour les fusionner ou les dissocier.
Module Exploitation/Traitement

Ce module permet de construire des requêtes d’interrogation de la base, via des associations de critères à l’aide d’opérateurs ensemblistes. Un dispositif de représentation sous forme d’arbre des requêtes devrait en faciliter l’interprétation. Il permet également d’historiser et de partager les requêtes entre les utilisateurs.
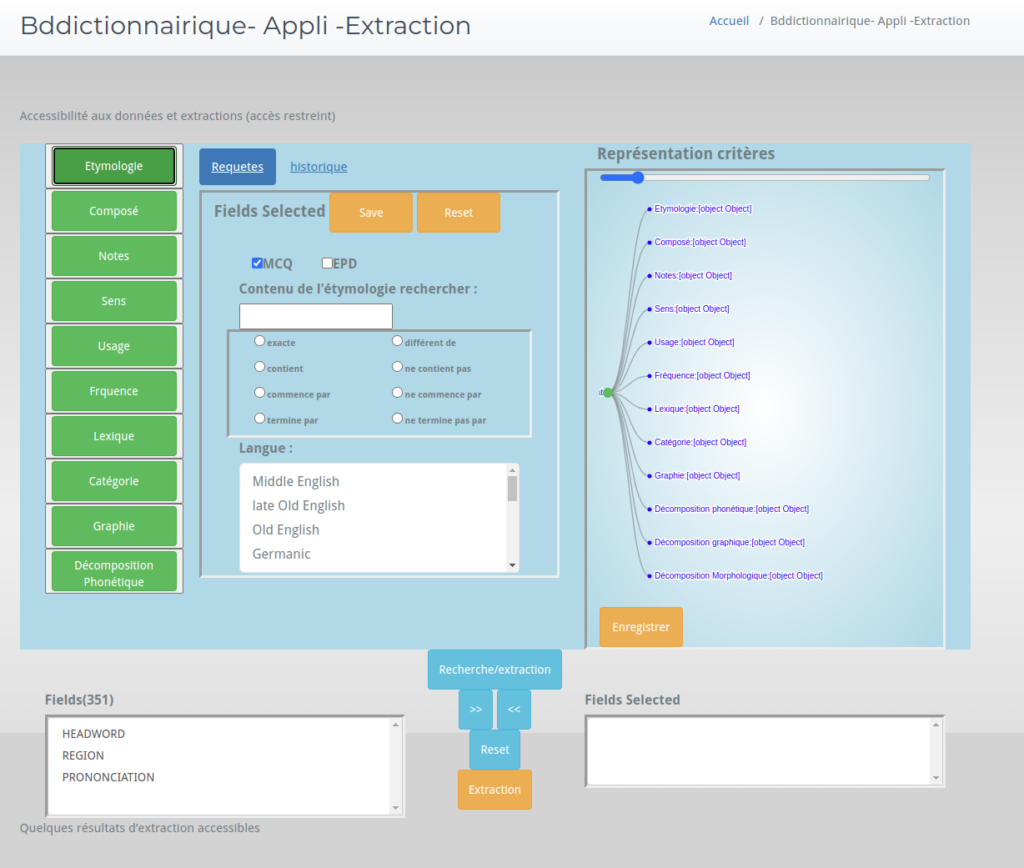
Module enrichissement

Ce module est prévu pour des ajouts d’informations/de données dans la base de données comme des fonds sonores, complément d’informations sur les entrées (structure morphologique, fréquences, relation nom/verbe etc) et toutes autres données que l’on souhaite relier à cette base.
Module Valo/comm/diffu

Ce module sert avant tout d’espace de communication et/ou de diffusion des actions, travaux effectués autour de ces données, on pourra croiser et relier les informations issues du site Morphophonologie Anglais Contemporain.
Exemples d’interprétation (voir)
Problèmes rencontrés (voir)